1. Activation Functions(비선형 연산)
ReLU를 사용하자! ReLU가 표준으로 많이 사용됨.
하지만, learning rate를 잘 결정해야 한다!

1) Sigmoid
- 단점: Saturated neurons kill the gradients
기울기가 0에 가까워지는 현상: Saturation -> Vanishing Gradient 문제를 일으킴
(backprop에서 0이 계속 전달됨) - 단점: Sigmoid outputs are not zero-centered
2) tanh
- 장점: zero centered는 해결됨
- 단점: still kills gradients when saturated
3) ReLU
- 장점: 양의 값에서는 saturation이 되지 않는다.
- 장점: 매우 빠름
- 단점: 음의 값에서는 saturation된다 0 -> gradient의 절반을 죽여버린다(dead ReLU)
-> 초기화 및 learning rate를 잘 설정해주어여 한다 - 단점: zero-centered가 해결되지 않았음.
2. Data Preprocessing
이미지에서는 주로 zero-centered

3. Weight Initialization
w가 너무 작으면 -> 출력값이 작아져서 -> 0이 되어버림 -> backprop에서 업데이트가 잘 일어나지 않음
w가 너무 크면 -> saturation이 일어남(tanh에서)
-> Xavier initialization을 사용하자!
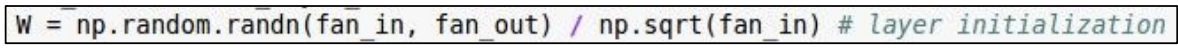
ReLU에서는 dead ReLU를 고려, 2로 나눈값으로 나눔!

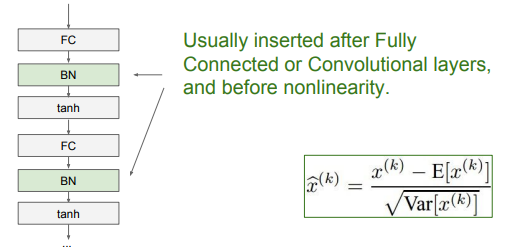
4. Batch Normalization
Batch Normalization은 하나의 layer가 추가된다고 생각하면 된다.
Batch Normalization은 Fully Connected Layer와 Activation Function 사이에 추가한다.


5. Babysitting the Learning Process
Step 1) Preprocess the data
Step 2) Choose the architecture
regularization을 enable 시키면 loss가 증가!
적절한 learning rate을 찾자!(너무 낮으면 loss가 줄어들지 않는다, 너무 높으면 loss가 너무 큼)

6. Hyperparameter Optimization
cross-validation strategy
random layout을 사용하는 것이 grid layout보다 최적 파라미터 찾는데에 적합
필요할 때는 log space

7. Monitor and visualize the accuracy
training accuracy와 validation accuracy가 크게 차이나면 -> overfitting문제가 발생하고 있음
-> increase regulaization strength!
'딥러닝 > cs231n' 카테고리의 다른 글
| 8. Deep Learning Software (0) | 2024.04.29 |
|---|---|
| 7. Training Neural Networks 2 (0) | 2024.04.29 |
| 5. Convolutional Neural Networks (0) | 2024.04.08 |
| 4. Introduction to Neural Networks (0) | 2024.04.02 |
| Lecture 3: Loss Function and Optimization (0) | 2024.04.01 |



