RNN: sequential 데이터 학습에 활용
수행하려는 task에 따라 다양한 수의 input과 output을 가짐(one-to-many, many-to-one, many-to-many)
RNN에는 hidden state가 추가됨
hidden state는 계속해서 업데이트 되지만, 함수 f와 파라미터 W는 매번 동일한 값을 가진다.



(예시) RNN을 이용하여 prefix가 주어졌을 때, 어떠한 문자가 출력되어야 하는 지 예측하는 예시

위 예씨의 경우 가장 스코어가 높은 값만 사용하게 되면 올바른 결과가 나오지 않는다.
확률분포를 사용해서 샘플링했기 때문에 hello를 만들어낼 수 있었는데, 확률분포에서 샘플링하는 방법을 통해 일반적으로 모델에서 다양성을 얻을 수 있게 된다.

RNN은 hidden state를 이용하여 계산시간과 학습시간이 느림
RNN에서는 sequence에 대해 back propagation을 수행해야 하므로, 계산량이 많기 때문에
잘라낸 신경망에서 역전파 수행
RNN-> 셰익스피어 글 생성, C코드 생성, Image Captioning, visual question answering 에 사용...
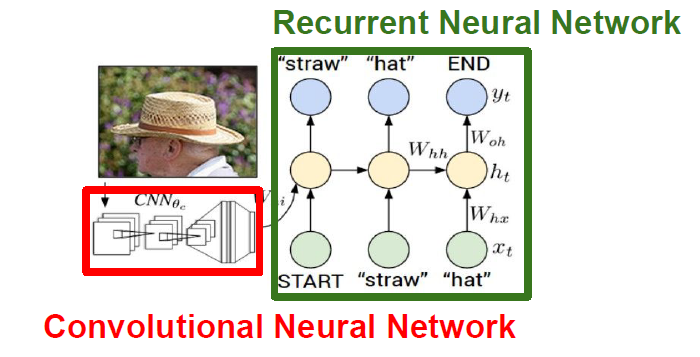
<Image Captioning>
입력은 이미지이고, 출력은 자연어로 된 caption
CNN에서 나오는 하나의 출력값을 RNN의 입력으로 사용
지도학습 수행

<Image Captioning with Attention>
caption을 생성할 때, 이미지의 특정부분을 집중적으로 볼 수 있음.
CNN의 출력으로 하나의 벡터를 만드는 것이 아니라, 각 벡터가 갖고 있는 공간 정보 grid of vector를 만들어냄.
attention은 각 이미지의 어느 부분을 중심적으로 볼지에 대한 정보


<RNN의 문제점>


W가 계속 곱해지게 되므로, exploding gradients/vanishing gradients 문제 발생
exploding gradient문제는 gradient clipping 기법 통해 해결(매번 값이 threshold보다 커질때마다 조정)
<LSTM>
이를 해결하기 위해 -> LSTM(Long Short Term Memory)
RNN과 유사한 구조이지만, cell state가 추가됨

ht: hidden state
ct: cell state(4개의 gate를 통해 업데이트)


이제 역전파 과정에서, W대신 f를 곱해주게 된다. f는 각 단계마다 input과 W의 곱으로 새로 생성되므로 매번 다른 값을 곱해주는 것이기 때문에 gradient vanishing 문제가 발생하지 않는다.
W에 대한 gradient 계산 또한 cell state로 전달된 역전파값이 사용되므로, 잘 이루어짐
<GRU>
LSTM의 변형
GRU가 LSTM보다 단순한 구조를 가져 학습이 더 빠름

'딥러닝 > cs231n' 카테고리의 다른 글
| 12. Visualizing and Understanding (0) | 2024.05.24 |
|---|---|
| 11. Detection and Segmentation (0) | 2024.05.24 |
| 9. CNN Architectures (0) | 2024.05.05 |
| 8. Deep Learning Software (0) | 2024.04.29 |
| 7. Training Neural Networks 2 (0) | 2024.04.29 |


