1. AlexNet (2012)
ImageNet classification task 잘 수행, First CNN-based winner

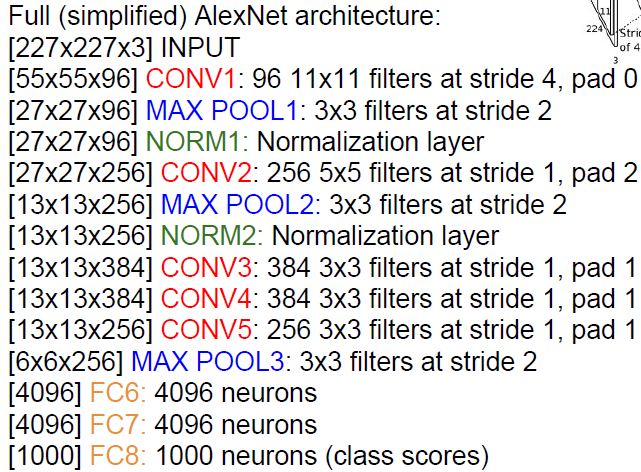
1) CONV1
227 x 227 x 3 input
filter: 96개의 11x11 필터(stride:4)
(227-11)/4+1=55
-> 55 x 55 x 96
파라미터 갯수 : (11*11*3)*96=35K
2) MAX POOL1
filter: 3x3(stride:2)
(55-3)/2+1=27
->27 x 27x 96
파라미터 갯수: 0
- 비선형함수로 ReLU 사용
- Regularization(data augmentation, dropout)
- optimization으로 SGD momentum 0.9
- Learning rate 1e-2
- ConvNet에서 2개 row로 나누는데 ([55x55x48]x2)
그 이유는 GTX580 GPU 3GB memory밖에 되지 않기 때문에 2개의 GPU로 나누어 진행.
2. VGGNet (2014)
smaller filters, deeper networks

작은 필터를 여러번 사용함!
3x3 conv(stride 1) 3개 stack==7x7 conv
deeper -> more non-linearlity -> 더 자세히 특징을 잡아낼 수 있다 & 파라미터 수가 적어짐

most memory is in early CONV
most params are in late FC
AlexNet: 60M parameters에 비해 파라미터 갯수는 138M으로 매우 많으며, 메모리 용량도 매우 크다.
3. GoogLeNet (2014)
- deeper network(22 layer)
- computational efficiency
- no FC layers
- 5M parameters
- Inception module
<Inception Module>
네트워크와 네트워크 사이에 있는 네트워크
여러 종류의 필터를 병렬적으로 같은 input layer에 적용해 나온 값들을 concatenate


inception module안에서 계산량이 많기 때문에 bottleneck layer를 통해 계산량을 줄임
-> 358M


- Auxiliary classification
-> 네트워크가 깊기 때문에 back propagation을 할 때, gradient vanishing 문제가 발생하기 쉽기 때문에 중간에 gradient와 loss를 계산해 놓아서 back propagation을 도와줌(training에만)
- 파라미터 수가 많은 FC layer가 없음!
4. ResNet (2015)
- 152 layers
네트워크가 깊어지면 깊어질수록 풍부한 특징 추출 가능,
하지만 무작정 깊어지면 성능이 저하됨.

deeper 모델에서 training, test에러 모두 늘어나는 문제가 발생함
이는 optimization 문제임
하지만, A solution by construction is copying the learned layers from the shallower model and setting
additional layers to identity mapping
-> Use network layers to fit a residual mapping instead of directly trying to fit a desired underlying mapping

CNN 20층에 input과 output을 동일한 값으로 출력해주는 layer 36층을 더 쌓아 56층을 만들면
적어도 CNN 20층일 때만큼의 성능은 나온다는 가정!
Residual Mapping: Conv layer를 통과한 F(X)와 Conv layer를 통과하지 않은 X를 더하는 과정
x : 입력 값
H(x) : CNN Layer -> ReLU -> CNN Layer -> ReLU 를 통과한 출력 값
F(x) : CNN Layer -> ReLU -> CNN Layer 을 통과한 출력 값
기존에는 H(x)=y가 되는 것이 목표
ResNet은 H(x)=x가 되는 것을 목표
-> F(x)=0이라는 목표값이 주어지기 때문에 학습이 더 쉬어짐.

모든 residual block은 3x3 conv 2층을 가진다.
주기적으로, double # of filters and downsample spatially using stride 2
GoogLeNet과 마찬가지로 bottleneck을 사용하기도 함!
- BatchNormalization after every Conv layer
- Mini-batch size 256
- Xavier/2 initialization
- SGD+Momentum(0.9)
- Learning rate: 0.1
- weight decay: 1e-5
- no dropout
5. 모델별 비교

원 크기: memory usage
VGG: Highest memory, most operations(computationally expensive)
GoogLeNet:most efficient
AlexNet: smaller compute, still memory heavy, lower accuracy
ResNet: moderate efficency depending on model, highest accuracy
6. 기타 architectures...
1) Network in Network(NiN)
Mlpconv layer within each conv layer
precursor to bottleneck layers

2) improved ResNet

3) wide residual networks
Increasing width instead of depth
more filters!

more computationally efficient
50 layer wide ResNet outperforms 152-layer original ResNet
4) ResNeXt

Increases width of residual block through multiple parallel pathways(cardinality)
5) Deep Networks with stochastic depth
randomly drop a subset of layers during each training pass / use full deep network at test time
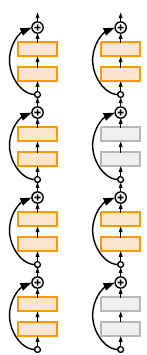
6) FractalNet
residual representations are not necessary!
7) Densely Connected Convolutional Networks
Dense blocks where each layer is connected to every other layer in feedforward fashion

8 )SqueezeNet
fire module을 도입하여 AlexNet-level Accuracy with 50x fewer parameters and <0.5Mb Model Size
ResNet: current best default!
'딥러닝 > cs231n' 카테고리의 다른 글
| 11. Detection and Segmentation (0) | 2024.05.24 |
|---|---|
| 10. Recurrent Neural Networks (0) | 2024.05.06 |
| 8. Deep Learning Software (0) | 2024.04.29 |
| 7. Training Neural Networks 2 (0) | 2024.04.29 |
| 6. Training Neural Networks 1 (0) | 2024.04.08 |



