1. 심층신경망
선형 회귀 또는 로지스틱 회귀는 비선형 문제를 풀 수 없음
비선형 데이터를 다루기 위해서 심층신경망이 필요함.
심층신경망은 세상에 존재하는 그 어떤 형태의 함수도 근사계산할 수 있음.
심층신경망: 선형계층을 쌓고, 그 사이에 비선형 활성함수를 끼워넣음

2. 역전파(back-propagation)
손실함수에 대해 미분을 하여 최적의 가중치 파라미터를 찾아야 하는데,
체인룰을 활용하여 효율적인 미분 계산 가능


3. 그래디언트 소실문제(gradient vanishing)
입력에 가까운 계층의 가중치 파라미터가 잘 업데이트 되지 않는 문제
활성함수 기울기가 1보다 작은데, 작은 그래디언트 값이 계속 곱해져서 생기는 문제

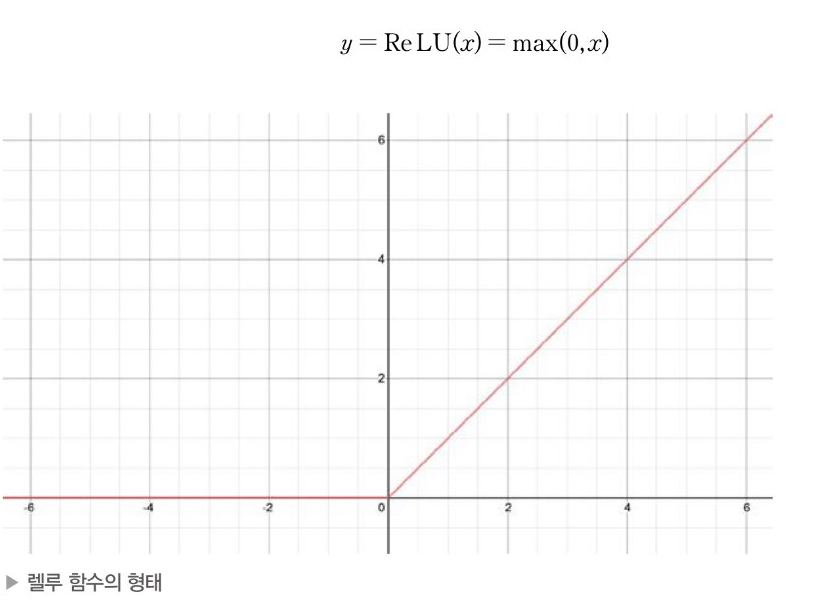
4. ReLU / leaky ReLU
그랜디언트 소실 문제를 보완하기 위한 활성함수
ReLU는 양수 구간에서 기울기가 1이어서 심층신경망이 매우 빠른 최적화가 나으하지만 음수 구간에서는 0이므로 영원이 업데이트 될 수 없는 문제 발생 -> 음수구간에서 기울기가 0이 아닌 leaky ReLU
하지만 그래디언트 소실 문제가 사라지지는 않음!

5. 실습
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_boston
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
boston=load_boston()
df=pd.DataFrame(boston.data, columns=boston.feature_names)
df["TARGET"]=boston.target
scaler=StandardScaler()
scaler.fit(df.values[:,:-1])
df.values[:,:-1]=scaler.transform(df.values[:,:-1]).round(4)
data=torch.from_numpy(df.values).float()
y=data[:,-1:]
x=data[:,:-1]
n_epochs=200000
learning_rate=1e-4
print_interval=10000
class MyModel(nn.Module):
def __init__(self, input_dim, output_dim):
self.input_dim=input_dim
self.output_dim=output_dim
super().__init__()
self.linear1=nn.Linear(input_dim,3)
self.linear2=nn.Linear(3,3)
self.linear3=nn.Linear(3,3)
self.linear4=nn.Linear(3,output_dim)
self.act=nn.ReLU()
def forward(self, x):
h=self.act(self.linear1(x))
h=self.act(self.linear2(h))
h=self.act(self.linear3(h))
y=self.linear4(h)
return y
model=MyModel(x.size(-1),y.size(-1))
print(model)
model2=nn.Sequential(
nn.Linear(x.size(-1),3),
nn.LeakyReLU(),
nn.Linear(3,3),
nn.LeakyReLU(),
nn.Linear(3,3),
nn.LeakyReLU(),
nn.Linear(3,y.size(-1))
)
optimizer=optim.SGD(model.parameters(), lr=learning_rate)
for i in range(n_epochs):
y_hat=model(x)
loss=F.mse_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if(i+1)%print_interval==0:
print('Epoch %d: loss=%.4e'%(i+1, loss))
정규화 후 모델만들고 training!
모델 만들 때, nn.Sequential 클래스 활용 가능!
[결과 시각화]
df=pd.DataFrame(torch.cat([y,y_hat],dim=1).detach().numpy(), columns=["y","y_hat"])
sns.pairplot(df, height=5)
plt.show()
'딥러닝 > 파이토치 딥러닝' 카테고리의 다른 글
| 12장. 오버피팅을 방지하는 방법 (0) | 2024.05.15 |
|---|---|
| 11장. 최적화 (0) | 2024.05.09 |
| 8장. 로지스틱 회귀 (1) | 2024.05.01 |
| 7장 선형회귀(linear regression) (0) | 2024.04.22 |
| 6장 경사하강법 (0) | 2024.04.22 |



